Teaching Machines to Unlearn
by Christopher A. Choquette-Choo, Varun Chandrasekaran, and Nicolas Papernot
With many contributions from paper co-authors Adelin Travers, Baiwu Zhang, David Lie, Hengrui Jia, and Lucas Bourtoule.
Have you ever wondered which organizations have access to your data? We share data with many organizations, be they online social platforms to communicate with friends, healthcare providers to benefit from personalized care, or retailers to receive personalized recommendations. Once shared, it can be difficult to understand and control who has access to our data. Over time, this can make it difficult to manage our privacy.
Even when we know which organizations have access to our data, it is not always clear how it can be deleted. This problem is exacerbated when machine learning was used to draw conclusions from our data, because information contained in our data may end up (memorized) in the machine learning model. In particular, models trained with deep learning are known to (unintendedly) memorize some of their training data.
This begs the question: what should an organization do with its machine learning models when users request that their data be deleted, after they previously agreed to share it? This is the problem we tackle in our “Machine Unlearning” paper to appear at the next IEEE Symposium on Security and Privacy.
Finding answers to this question is particularly pressing given that recent legislation requires organizations to give users the ability to delete their data (e.g., GDPR, Right to be forgotten). These pieces of legislation call for increased clarity around data usage in policy and technology. Thus, we now need the ability to make a trained machine learning model forget anything it could have learned from specific data samples.
What is unlearning?
In unlearning research, we aim to develop an algorithm that can take as its input a trained machine learning model and output a new one such that any requested training data (i.e., any data originally used to create the machine learning model), has now been removed. A naive strategy is to retrain the model from scratch without the training data that needs to be unlearned. However, this comes at a high computational cost; unlearning research seeks to make this process more efficient.
Let’s describe the problem a bit more formally so we can see how it differs from other definitions of privacy. We denote the user data that is requested to be unlearned as d_u. We need to develop an unlearning algorithm that outputs the same distribution of models as retraining without d_u (the naive solution), which is our (strict) deterministic definition that we explore to better align with the goals of new privacy legislation; in this setting, we certainly unlearn the entirety of d_u’s contributions. If these distributions do not match, then there is necessarily some influence from d_u that has led to this difference. Settings where an unlearning algorithm only approximately matches the retraining distribution can be viewed as a (relaxed) probabilistic setting, where we unlearn most (but not all) of d_u’s contributions.
Such an example of a probabilistic definition of privacy is already found in the seminal work on differential privacy, which addresses a different but related definition of privacy than what unlearning seeks to achieve. For readers familiar with the definition of differential privacy, one can think of satisfying the strict privacy definition behind unlearning through differential privacy as requiring that we learn a model with an algorithm that satisfies ε=0. Of course, this would prevent any learning and destroy the utility of the learned model. Research in this relaxed setting of unlearning may be able to further reduce computational load, but the guarantee is difficult for non-experts to grasp and may not comply with all regulatory needs.
Why is unlearning difficult?
In general, it is very difficult to provably unlearn a data point, because to erase its contributions we would first have to calculate them so as to remove them. In most of machine learning (especially deep learning), the learning process is incremental, meaning that we start with some model and incrementally improve or update it. The stochasticity combined with the “unpredictable” data-order dependence involved in training deep learning models makes it difficult to attribute specific model parameter contributions to a given data point (see the work of Cao and Yang for instance). Our work is the first to enable deterministic unlearning for a broad class of these complex, incrementally (or, adaptively) learned ML models.
How do we perform unlearning?
We now describe our approach to unlearning. We illustrate it with a single unlearning request (i.e., delete du), but the procedure for processing multiple such requests concurrently is similar.
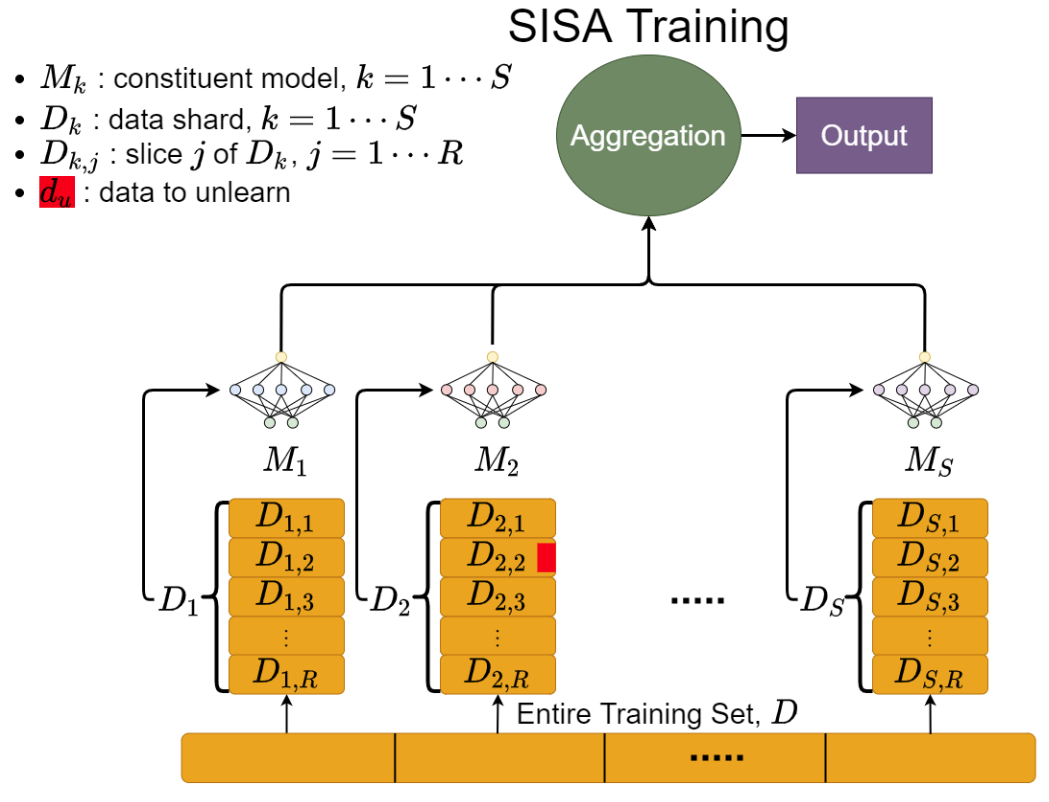
We improve over the strawman strategy of retraining a model from scratch in two ways:
Our first optimization is called sharding. Recall that retraining a model without d_u is computationally intensive and time consuming when we have a large dataset; sharding aims to reduce this resource usage. In sharding, we partition the dataset into disjoint partitions (or shards). We then train a separate model, called a constituent model, on each shard. When making predictions, we ask all of the constituent models to vote and output the class which received the most number of votes. The sharding procedure ensures that each point is in only one of the shards and its influence is restricted to that particular constituent model, since the constituent models were trained in isolation. Now, an unlearning request can be mapped to a particular shard, where only the constituent model trained on that shard needs to be retrained. This approach speeds up retraining by (a) reducing the total number of data points that are affected by an unlearning request and (b) reducing the volume of data used to train each of the constituent models.
For example, imagine 1,000,000 data points are evenly split into S=10 shards, where each shard has 100,000 data points. On arrival of an unlearning request (after sharding), only the constituent model corresponding to the affected shard needs to be retrained – amounting to retraining a model with 99,999 points. The baseline would require retraining of the large “monolithic” model with 999,999 points, which is nearly 10x more data. This result can be generalized: for a single unlearning request, on creating N shards, the speed-up is N-fold.
Our second optimization is called slicing. We divide the data in a shard into disjoint subsets; each subset is called a slice. We then train a new model by ‘fine-tuning’ on incremental sets of slices, as opposed to including all the data in the shard in each of the epochs during training. We find that this process yields a final model that has comparable prediction accuracy to a model trained without slicing. It also decreases the time needed to retrain the model if we save a checkpoint, or intermediate model, of the model before introducing the next slice in training, which we must do since each new slice introduces new user data that may need to be unlearned.
For example, if a shard is divided into R=5 slices (say slice 1 to slice 5), we first train intermediate model 1 using slice 1, and then train intermediate model 2 by fine-tuning model 1 on both slice 1 and slice 2. We do so until we’ve trained our final model, model 5, which we do by fine tuning model 4 with data from slices 1 through 5; we use model 5 to make predictions. This process can be easily implemented using model checkpoints – saved, backup model parameters from different stages of training that are very common to ML pipelines. To unlearn d_u, we need only retrain all (intermediate) models that were trained/fine-tuned using the slice containing d_u. In the worst-case, this data point will be in slice 1, where we will have to retrain all models; however, in expectation we will only have to retrain half of them. As before, we can use any unaffected models to speed-up the fine-tuning process, which we find leads to an average 1.5-fold reduction in training time.
At best, we can achieve a 1.5N-fold speed-up for a single unlearning request by using our techniques, collectively called Sharded Isolated Sliced Aggregated (SISA) training. For more unlearning requests, we incur more retraining costs when the unlearned data points fall into new shards or slices because we would then have more models to retrain. Our paper contains more details for evaluating speed-ups when we receive higher volumes of unlearning requests. Our evaluation shows that we can efficiently handle more unlearning requests than shown by available historical data on search engines.
What is the impact of unlearning on machine learning performance?
Aggregation: As we have now introduced more (>1) models into our machine learning framework, we have to understand how to aggregate the knowledge from each model when making a prediction. An important consideration of our sharding strategy is that the reduced amount of data per model (which improves training time) may now make models less accurate. Our evaluations on neural networks show that by combining the predictions of each model, we can achieve only a marginal decrease in accuracy (about 1 percentage point decrease) for simple learning tasks, such as MNIST, SVHN, etc., as defined in our paper. For simplicity, we often use a simple majority voting strategy and return the prediction which received the most votes, but we also explore other methods as detailed in our paper. We find that the choice of aggregation strategy and number of shards becomes more important as we have harder tasks (such as ImageNet, CIFAR-100 classification) or less data because sharding can lead to significant degradation of prediction accuracy.
Sharding, Slicing, or both? Both sharding and slicing can be carried out independently (i.e., without the other). Slicing avoids accuracy degradation and the need for an aggregation strategy, but comes at the expense of additional storage. This additional storage is nonetheless cheaper than computational hardware and time cost that we trade off. Sharding does not incur any storage overheads, but has the potential for accuracy degradation. The accuracy degradation incurred by sharding necessitates that we now best choose the number of shards: too many and our aggregate model will not perform well, whereas too few will limit the speed-ups we gain.
What if we know who is more likely to request unlearning? In our paper we also explore how much better we can serve unlearning requests if we know, apriori, which points may be more likely to be unlearned. Our work shows that if there is any non-uniform knowledge, we can further improve retraining speed-ups by modifying the way data is partitioned for sharding and slicing. However, there are many challenges to consider in these adaptive methods, such as bias in learning. For example, it could be possible that users who are more likely to request data deletion are also marginalized; both our training algorithm and unlearning procedure should still lead to fair models that can predict well for these users. We discuss these issues in more detail in our paper.
Conclusion
Achieving strict unlearning, i.e., entirely forgetting a data point’s contributions is difficult because we cannot efficiently calculate its entire contributions to a complex model. However, unlearning is important to consider in training and releasing machine learning models to comply with our evolving privacy legislation. We hope that our work on SISA training will spur interest from the community in designing new machine learning algorithms that make it easier to unlearn.
To learn more
For more details, please refer to our paper, which can be found here. We also open-sourced our code here. A set of blog posts going into more details about machine unlearning can be found here.