How to Keep a Model Stealing Adversary Busy?
by Adam Dziedzic, Muhammad Ahmad Kaleem, and Nicolas Papernot
This blog post is part of a series on model stealing, check out our previous blog post “Is this model mine?” for a general introduction to the problem.
Machine learning APIs are increasingly pervasive. Many companies adopt a pay-per-use system, where their ML model is deployed through a cloud service and clients pay to query the model. That said, they expose the predictions of models that are expensive to train and thus highly valuable. For example, it was reported that a single training run of the GPT-3 model costs north of $12 Million.
Nonetheless, displaying a model in such a fashion leaks information on the model itself and thus exposes it to being stolen by malicious third parties, that is to train a copy of the victim model at a lower cost than training an equivalent model from scratch [1,2]. According to a survey [3] that was based on responses from 28 different organizations, model stealing is one of the top-3 most severe attacks. Model stealing can also be used as a preparation to mount other attacks. For example, after extracting a model, the attacker can use the stolen copy to craft adversarial examples.
In this blog post and in the complementary talk below, we outline our method on how to prevent model stealing attacks.
Model Stealing Attacks
Let’s start with some intuition as to how model stealing attacks work. Typically, an attacker sends legitimate but carefully crafted queries to the target ML API, which reveals in return the model’s outputs. These outputs are used by an attacker to train the stolen copy of the victim model at a lower cost than training the victim model from scratch. This is possible because the returned model’s output predictions reveal information extracted from the training set; which makes it easier to learn a copy of the victim model than to train the victim model from raw training data.
There are many approaches to stealing models. We invite you to read our paper for an overview. The main differentiating point behind these attacks is how they generate queries made to the victim model. The more information the adversary has about the data distribution, the easier it is to craft queries that extract a higher amount of information about the victim model. A defender wants to defend against any of these attacks while limiting the impact of the defense on legitimate users. For example, the defense could degrade the quality of model outputs to prevent model stealing, but it would also decrease the quality of service to the legitimate users.
Model Extraction Defenses
How can we defend against model extraction? As we have just said, some defenses sacrifice the accuracy of predictions returned to users querying the model to limit how much an adversary may learn about the model through these queries [1,4]. Others attempt to detect queries that deviate from common legitimate user queries and stop answering subsequent queries made by the adversary [5]. Finally, approaches like watermarking or dataset inference set out to detect model stealing after the fact [6].
Instead, we propose a proactive defense that tackles model extraction as it is happening. Our defense increases the cost of model extraction during the theft rather than detecting it post hoc. It also differs from prior defenses in that it does not introduce a tradeoff with the quality (e.g., accuracy) of model outputs.
Proof of work as a defense against model stealing
To avoid this tradeoff, we draw inspiration from the concept of proof-of-work (PoW). Techniques for PoW were initially used to prevent Denial-of-Service attacks, where adversaries flood a server with superfluous requests, overwhelming the server and degrading service for legitimate users. PoW techniques provide users with a small puzzle to be solved before giving access to the service. For instance, an email provider could ask each user to solve a small puzzle before being able to send an email: this makes it more expensive for an adversary to send lots of spam emails.
Our defense requires users to expend some computation by solving a PoW puzzle before receiving predictions from an ML API. This can prevent a malicious user from obtaining enough examples labeled by a victim model to steal the model. At the very least, it increases the computational cost of the attack. Indeed, our method shifts the trade-off between the quality of the API’s answers and its robustness to model stealing, which was introduced by previous defenses, to a trade-off between the computational cost of querying the API and its robustness to model stealing.
We reduce the impact on legitimate users by adjusting the difficulty of the required work for the PoW puzzle to individual queries. We draw from privacy research to calibrate the difficulty: the more a query leaks about the training set, the higher the difficulty is. We estimate this leakage using analysis techniques from differential privacy literature (we give more details later in this blog post). Then, the client solves the puzzle and sends the solution back to the server. The server verifies the solution and if it is correct, returns the label.
Our method is only one way to implement a proactive defense and it is based on proof-of-work. It allows alternative implementations that could reduce the energy usage, for example, by using proof-of-elapsed-time (PoET). Another solution is to increase the monetary cost of queries based on their incurred privacy leakage.
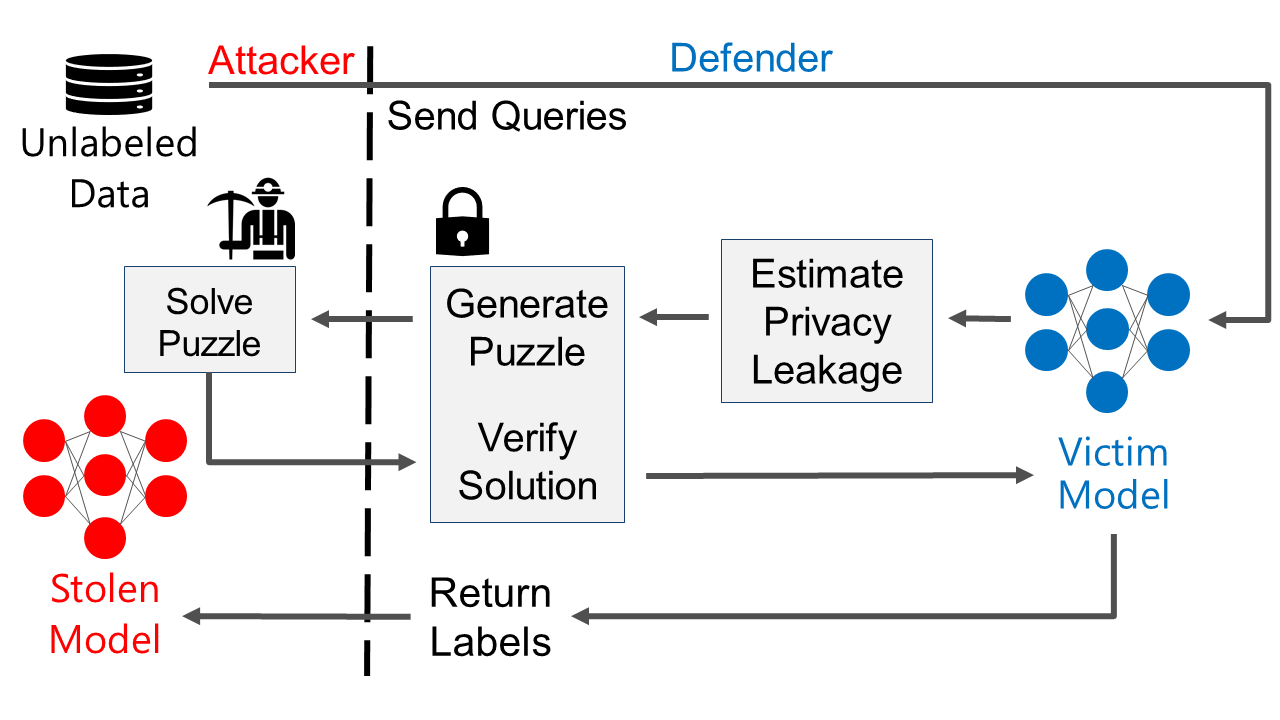
Calibrating the difficulty of PoW puzzles
We now dive into more details on how we quantify the information leaked by each query answered by the victim model. We use a differential privacy analysis via the PATE framework. Next, we generate a puzzle whose difficulty is calibrated using the estimated privacy cost.
To generate the puzzle, we use the Binary Hash Cash algorithm. The ML API sends a challenge string S to a user submitting a query. To solve the puzzle, the user has to brute-force search for a suffix X that gives a hash of S concatenated with X such that there are at least a specific number of leading zeros in the hash. In general, the more leading zeros required by the API, the more difficult the puzzle is.
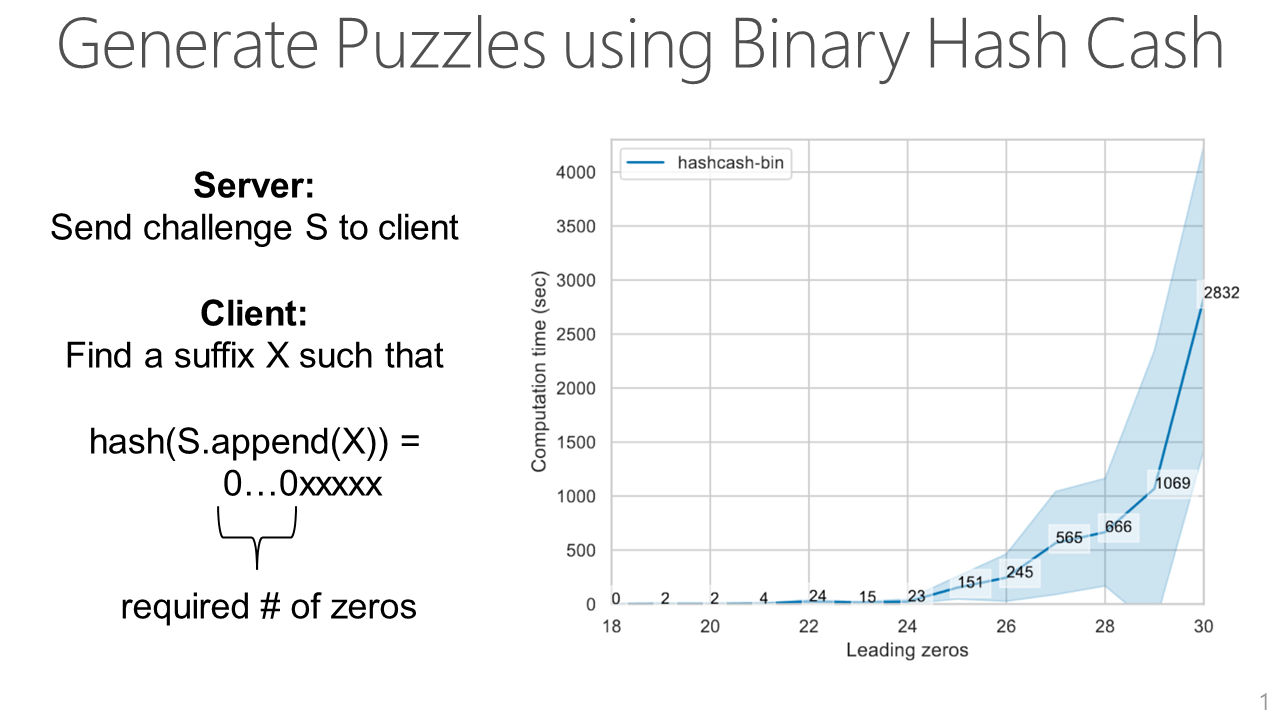
Next, we show how calibrating the difficulty of the puzzle with the privacy cost of a query increases the cost of attacker queries but has a negligible impact on legitimate users.
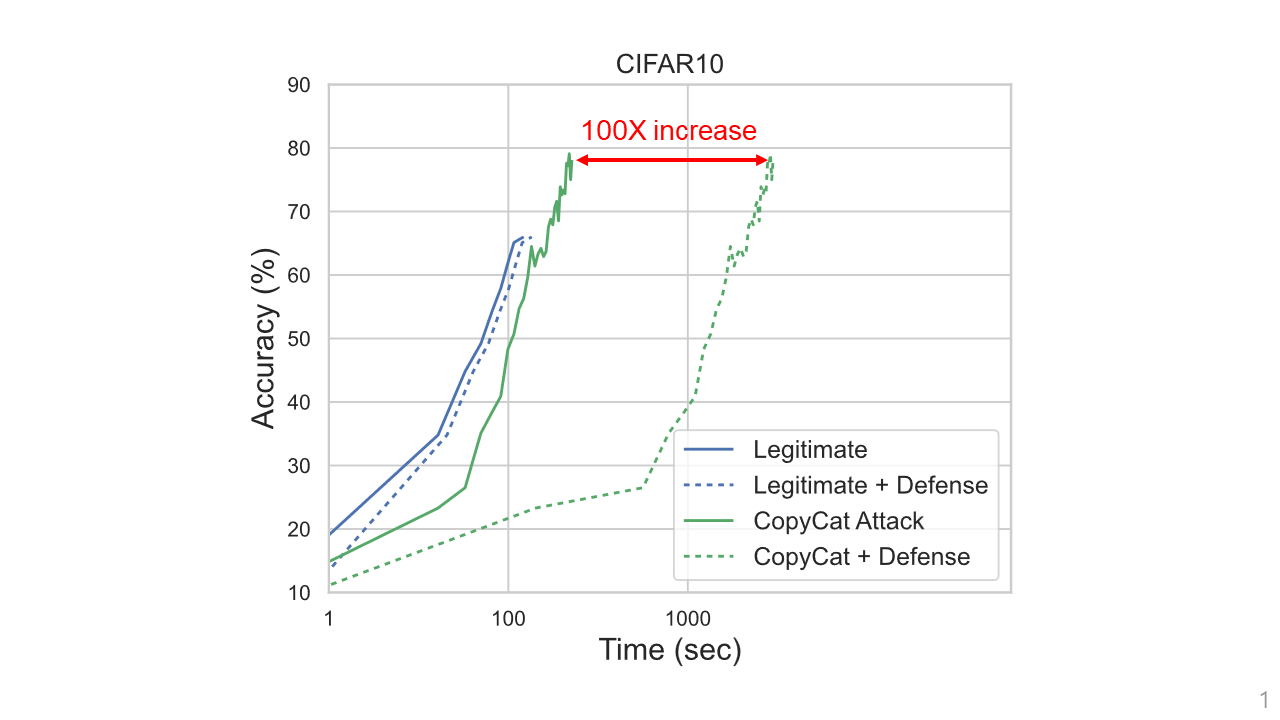
So, how does our defense perform? Let’s compare the accuracy of the stolen model as a function of the time it takes to run the queries needed to steal the model. In our defense, the model owner can adjust how much increase in the query time is acceptable for a legitimate user. In our experiments, we set it to be at most 2X. Instead, for attackers (like those using the Jacobian or CopyCat attacks) the cost increase is much more significant. For instance, a CopyCat adversary faces a 100x increase. We also show that it is difficult for an adversary to adapt their querying strategy to limit the overhead they face with our PoW mechanism.
Want to read more?
You can find additional details in our main paper [7]. The code for reproducing all our experiments is available in our GitHub repository.
Acknowledgments
Thank you to Adelin Travers for his detailed feedback on a draft of this blog post.
[1] Florian Tramèr, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning models via prediction APIs. USENIX 2016.
[2] Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, Nicolas Papernot. High Accuracy and High Fidelity Extraction of Neural Networks. USENIX 2020.
[3] Ram Shankar Siva Kumar, Magnus Nyström, John Lambert, Andrew Marshall, Mario Goertzel, Andi Comissoneru, Matt Swann, Sharon Xia. Adversarial Machine Learning – Industry Perspectives. arXiv 2021.
[4] Tribhuvanesh Orekondy, Bernt Schiele, Mario Fritz. Prediction poisoning: Towards defenses against dnn model stealing attacks. ICLR 2020.
[5] Mika Juuti, Sebastian Szyller, Samuel Marchal, N. Asokan. PRADA: Protecting against DNN Model Stealing Attacks. EURO S\&P 2019.
[6] Pratyush Maini, Mohammad Yaghini, Nicolas Papernot. Dataset Inference: Ownership Resolution in Machine Learning. ICLR 2021.
[7] Adam Dziedzic, Muhammad Ahmad Kaleem, Yu Shen Lu, Nicolas Papernot. Increasing the Cost of Model Extraction with Calibrated Proof of Work. ICLR 2022.